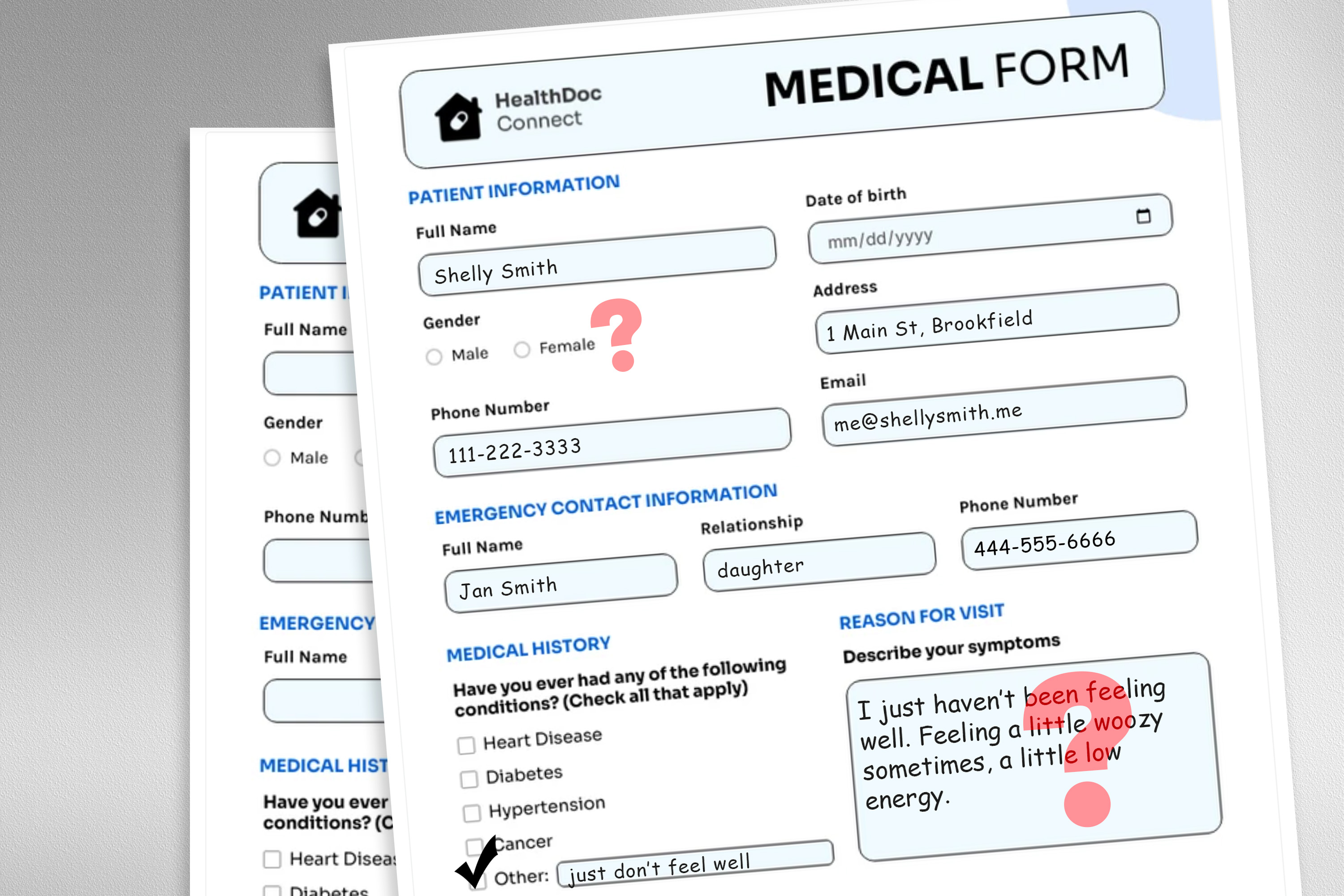
An MIT study finds non-clinical information in patient messages, like typos, extra whitespace, or colorful language, can reduce the accuracy of a large language model deployed to make treatment recommendations. The LLMs were consistently less accurate for female patients, even when all gender markers were removed from the text.


What kind of irrational lunatic would seriously attempt to invoke currently available Counterfeit Cognizance to obtain a “treatment recommendation” for anything…???
FFS.
Anyone who would seems a supreme candidate for a Darwin Award.
Not entirely true. I have several chronic and severe health issues. ChatGPT provides nearly and surpassing medical advice (heavily needs re-verified) from multiple specialialty doctors. In my country doctors are horrible. This bridges the gap albeit again highly needing oversight to be safe. Certainly has merit though.
Bridging the gap is something sorely needed and LLMs are damn close to achieving.
There’s a potentially justifiable use case in training one and evaluating its performance for use in, idk, triaging a mass-casualty event. Similar to the 911 bot they announced the other day.
Also similar to the 911 bot, i expect it’s already being used to justify cuts in necessary staffing so it’s going to be required in every ER to
maintain higher profit marginsjust keep the lights on.