

This is the technology worth trillions of dollars huh
GitLab Enterprise somewhat recently added support for Amazon Q (based on claude) through an interface they call “GitLab Duo”. I needed to look up something in the GitLab docs, but thought I’d ask Duo/Q instead (the UI has this big button in the top left of every screen to bring up Duo to chat with Q):
(Paraphrasing…)
ME: How do I do X with Amazon Q in GitLab? Q: Open the Amazon Q menu in the GitLab UI and select the appropriate option.
ME: [:looks for the non-existant menu:] ME: Where in the UI do I find this menu?
Q: My last response was incorrect. There is no Amazon Q button in GitLab. In fact, there is no integration between GitLab and Amazon Q at all.
ME: [:facepalm:]
I don’t think this gets nearly enough visibility: https://www.academ-ai.info/
Papers in peer-reviewed journals with (extremely strong) evidence of AI shenanigans.
Thanks for sharing! I clicked on it with cynicism around how easily we could detect AI usage with confidence vs. risking making false allegations, but every single example on their homepage is super clear and I have no doubts - I’m impressed! (and disappointed)
Yup. I had exactly the same trepidation, and then it was all like “As an AI model, I don’t have access to the data you requested, however here are some examples of…”
I have more contempt for the peer reviewers who let those slide into major journals, than for the authors. It’s like the Brown M&M test; if you didn’t spot that blatant howler then no fucking way did you properly check the rest of the paper before waving it through. The biggest scandal in all this isn’t that it happened, it’s that the journals involved seem to be almost never retracting them upon being reported.
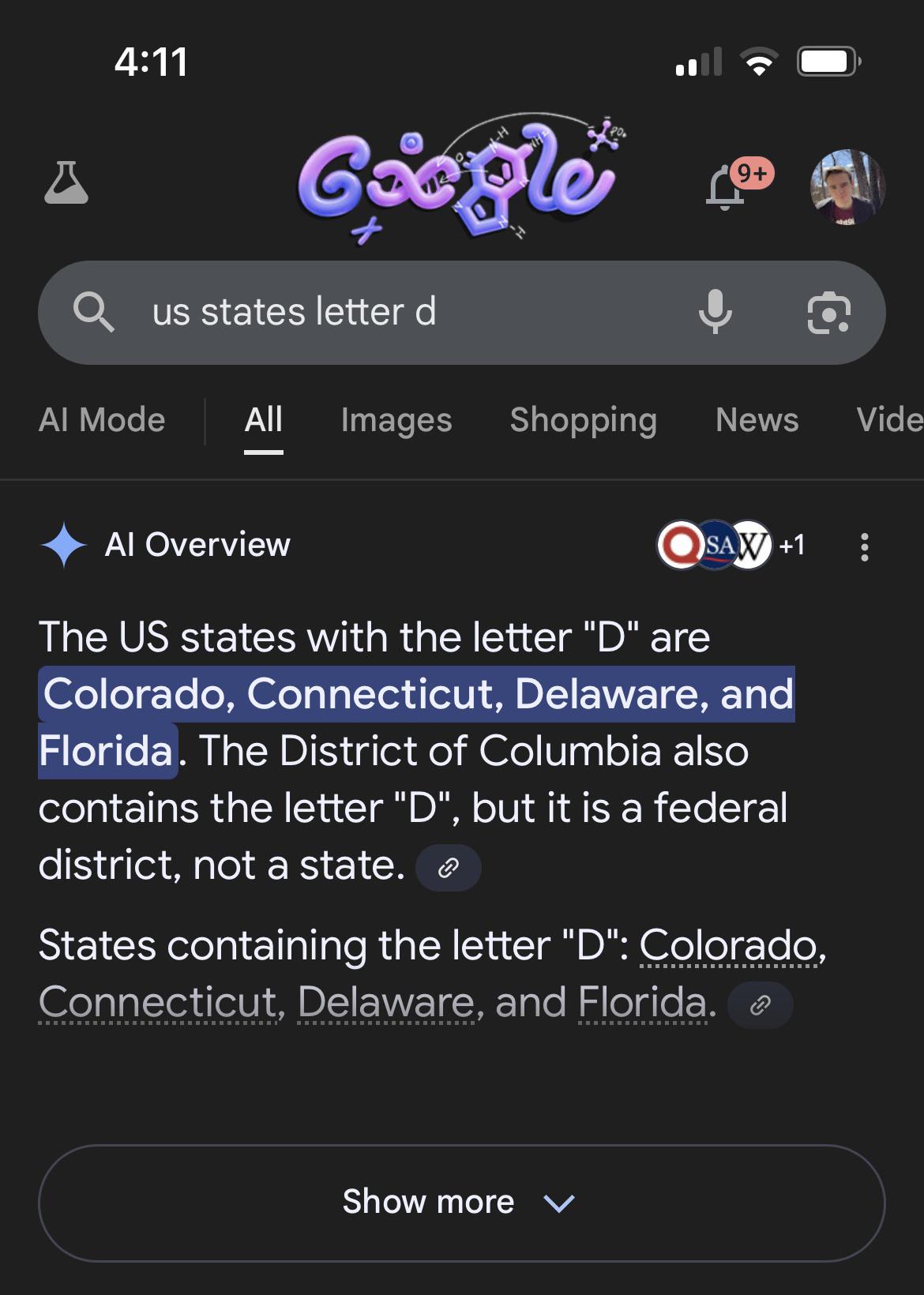
✅ Colorado
✅ Connedicut
✅ Delaware
❌ District of Columbia (on a technicality)
✅ Florida
But not
❌ I’aho
❌ Iniana
❌ Marylan
❌ Nevaa
❌ North Akota
❌ Rhoe Islan
❌ South Akota
Gosh tier comment.
You just described most of my post history.
Everyone knows it’s properly spelled “I, the ho” not Idaho. That’s why it didn’t make the list.
They took money from cancer reaearch programs to fund this.
After we pump another hundred trillion dollars and half the electricity generated globally into AI you’re going to feel pretty foolish for this comment.
Just a couple billion more parameters, bro, I swear, it will replace all the workers
- CEOs
only cancer patients benefit from cancer research, CEOs benefit from AI
Tbf cancer patients benefit from AI too tho a completely different type that’s not really related to LLM chatbot AI girlfriend technology used in these.
Well as long as we still have enough money to buy weapons for that one particular filthy genocider country in the middle east, we’re fine.
With enough duct tape and chewed up bubble gum, surely this will lead to artificial general intelligence and the singularity! Any day now.
Hurry MacGruber! We’re almost out of…BOOM!
It ripped off this famous poem in the process:
I would estimate that Google’s AI is helpful and correct about 7% of the time, for actual questions I’d like the answer to.
Connecdicud.
Connedicut.
I wondered if this has been fixed. Not only has it not, the AI has added Nebraska.
You mean Connecdicud.
What about Our Kansas? Cause according to Google Arkansas has one o in it. Refreshing the page changes the answer though.
Just checked, it sure does say that! AI spouting nonsense is nothing new, but it’s pretty ironic that a large language model can’t even parse what letters are in a word.
Well I mean it’s a statistics machine with a seed thrown in to get different results on different runs. So really, it models the structure of language, but not the meaning. Kinda useless.
I would assume it uses a different random seed for every query. Probably fixed sometimes, not fixed other times.
Stop using Google search, easy as that! I use duckduckgo and I have turned off AI prompts.
So this is the terminator consciousness so many people are scared will kill us all…
Well, for anyone who knows a bit about how LLMs work, it’s pretty obvious why LLMs struggle with identifying the letters in the words
Well go on…
Which is State contains 狄? They use a different alphabet, so understanding ours is ridiculous.
They don’t look at it letter by letter but in tokens, which are automatically generated separately based on occurrence. So while ‘z’ could be it’s own token, ‘ne’ or even ‘the’ could be treated as a single token vector. of course, ‘e’ would still be a separate token when it occurs in isolation. You could even have ‘le’ and ‘let’ as separate tokens, afaik. And each token is just a vector of numbers, like 300 or 1000 numbers that represent that token in a vector space. So ‘de’ and ‘e’ could be completely different and dissimilar vectors.
so ‘delaware’ could look to an llm more like de-la-w-are or similar.
of course you could train it to figure out letter counts based on those tokens with a lot of training data, though that could lower performance on other tasks and counting letters just isn’t that important, i guess, compared to other stuff
Of course, when the question asks “contains the letter _” you might think an intelligent algorithm would get off its tokens and do a little letter by letter analysis. Related: ChatGPT is really bad at chess, but there are plenty of algorithms that are super-human good at it.
Good read. Thank you
Con-ned-di-cut
Wouldn’t that only explain errors by omission? If you ask for a letter, let’s say D, it would omit words containing that same letter when in a token in conjunction with more letters, like Da, De, etc, but how would it return something where the letter D isn’t even in the word?
Well each token has a vector. So ‘co’ might be [0.8,0.3,0.7] just instead of 3 numbers it’s like 100-1000 long. And each token has a different such vector. Initially, those are just randomly generated. But the training algorithm is allowed to slowly modify them during training, pulling them this way and that, whichever way yields better results during training. So while for us, ‘th’ and ‘the’ are obviously related, for a model no such relation is given. It just sees random vectors and the training reorganizes them tho slowly have some structure. So who’s to say if for the model ‘d’, ‘da’ and ‘co’ are in the same general area (similar vectors) whereas ‘de’ could be in the opposite direction. Here’s an example of what this actually looks like. Tokens can be quite long, depending how common they are, here it’s ones related to disease-y terms ending up close together, as similar things tend to cluster at this step. You might have an place where it’s just common town name suffixes clustered close to each other.
and all of this is just what gets input into the llm, essentially a preprocessing step. So imagine someone gave you a picture like the above, but instead of each dot having some label, it just had a unique color. And then they give you lists of different colored dots and ask you what color the next dot should be. You need to figure out the rules yourself, come up with more and more intricate rules that are correct the most. That’s kinda what an LLM does. To it, ‘da’ and ‘de’ could be identical dots in the same location or completely differents
plus of course that’s before the llm not actually knowing what a letter or a word or counting is. But it does know that 5.6.1.5.4.3 is most likely followed by 7.7.2.9.7(simplilied representation), which when translating back, that maps to ‘there are 3 r’s in strawberry’. it’s actually quite amazing that they can get it halfway right given how they work, just based on ‘learning’ how text structure works.
but so in this example, us state-y tokens are probably close together, ‘d’ is somewhere else, the relation between ‘d’ and different state-y tokens is not at all clear, plus other tokens making up the full state names could be who knows where. And tien there’s whatever the model does on top of that with the data.
for a human it’s easy, just split by letters and count. For an llm it’s trying to correlate lots of different and somewhat unrelated things to their ‘d-ness’, so to speak
Thank you very much for taking your time to explain this. if you don’t mind, do you recommend some reference for further reading on how llms work internally?
For the byte pair encoding (how those tokens get created) i think https://bpemb.h-its.org/ does a good job at giving an overview. after that i’d say self attention from 2017 is the seminal work that all of this is based on, and the most crucial to understand. https://jtlicardo.com/blog/self-attention-mechanism does a good job of explaining it. And https://jalammar.github.io/illustrated-transformer/ is probably the best explanation of a transformer architecture (llms) out there. Transformers are made up of a lot of self attention.
it does help if you know how matrix multiplications work, and how the backpropagation algorithm is used to train these things. i don’t know of a good easy explanation off the top of my head but https://xnought.github.io/backprop-explainer/ looks quite good.
and that’s kinda it, you just make the transformers bigger, with more weight, pluck on a lot of engineering around them, like being able to run code and making it run more efficientls, exploit thousands of poor workers to fine tune it better with human feedback, and repeat that every 6-12 month for ever so it can stay up to date.
Thank you very much
You could look up 3Blue1Brown’s explainers on YouTube, they are pretty good and shows a lot of visual examples. He has a lot of other videos on other areas of math.
I’ll check it later, thanks
Just another trillion, bro.
Just another 1.21 jigawatts of electricity, bro. If we get this new coal plant up and running, it’ll be enough.
Behold the most expensive money burner!
Blows my mind people pay money for wrong answers.
You joke, but I bet you didn’t know that Connecticut contained a “d”
I wonder what other words contain letters we don’t know about.
The famous ‘invisible D’ of Connecticut, my favorite SCP.
That actually sounds like a fun SCP - a word that doesn’t seem to contain a letter, but when testing for the presence of that letter using an algorithm that exclusively checks for that presence, it reports the letter is indeed present. Any attempt to check where in the word the letter is, or to get a list of all letters in that word, spuriously fail. Containment could be fun, probably involving amnestics and widespread societal influence, I also wonder if they could create an algorithm for checking letter presence that can be performed by hand without leaking any other information to the person performing it, reproducing the anomaly without computers.
ct -> d is a not-uncommon OCR fuck up. Maybe that’s the source of it’s garbage data?
No, LLMs produce the most statistically likely (in their training data) token to follow a certain list of tokens (there’s nothing remotely resembling reasoning going on in there, it’s pure hard statistics, with some error and randomness thrown in), and there are probably a lot more lists where Colorado is followed by Connecticut than ones where it’s followed by Delaware, so they’re obviously going to be more likely to produce the former.
Moreover, there aren’t going to be many texts listing the spelling of states (maybe transcripts of spelling bees?), so that information is unlikely to be in their training data, and they can’t extrapolate because it’s not really something they do and because they use words or parts of words as tokens, not letters, so they literally have no way of listing the letters of a word if said list is not in their training data (and, again, that’s not something we tend to write, and if we did we wouldn’t include d in Connecticut even if we were reading a misprint). Same with counting how many letters a word has, and stuff like that.
SCP-00WTFDoC (lovingly called “where’s the fucking D of Connecticut” by the foundation workers, also “what the fuck, doc?”)
People think it’s safe, because it’s “just an invisible D”, not even a dick, just the letter D, and it only manifests verbally when someone tries to say “connecticut” or write it down. When you least expect it, everyone heard “Donnedtidut”, everyone read that thing and a portal to that fucking place opens and drags you in.
Words are full of mystery! Besides the invisible D, Connecticut has that inaudible C…
I hear the Invisible D and Silent C are happily married.
Every American I know does pronounce it like Connedicut 🤔
Really? Everyone I know calls it kinetic-cut. But I group up in new england.
“Kinetic” with a hard “T” like posh Brit is saying it to the queen? Everyone I’ve ever heard speaking US English pronounces it with a rolled “t” like “kinedic” so the alternate pronunciation still reads like it’d have a “d” sound
This phenomenon is called “T flapping” and it is common in North American English. I got into an argument with my dad who insisted he pronounces the T’s in ‘butter’ when his dialect, like nearly all North Americans pronounces the word as ‘budder’.
budder is softer than t flapping. further forward with the tongue on the palate.
It’s an approximation, but the t is partially vocalized giving it a ‘d’ sound even if it’s not made exactly the same way.
i just thought we were getting technical about the linguistics. i got and use both words frequently, thought the distinction might be appreciated. the difference is so subtle we sometimes have to ask each other which one we’re referring to. i’m willing to bet it shows up more on my face than in my voice.
That’s how I’ve always heard it pronounced on the rare occasions anybody ever mentions it. But I’ve never been to that part of the US so maybe the accents different there?
The d in Connecticut is between the e and the i. They don’t connect because it was cut.
Connecticut is Jewish?
Connedicut
I was going to make a joke if you’re from connedicut you never pronounce first d in the word. Conne-icut













{kind=link}
{kind=link}